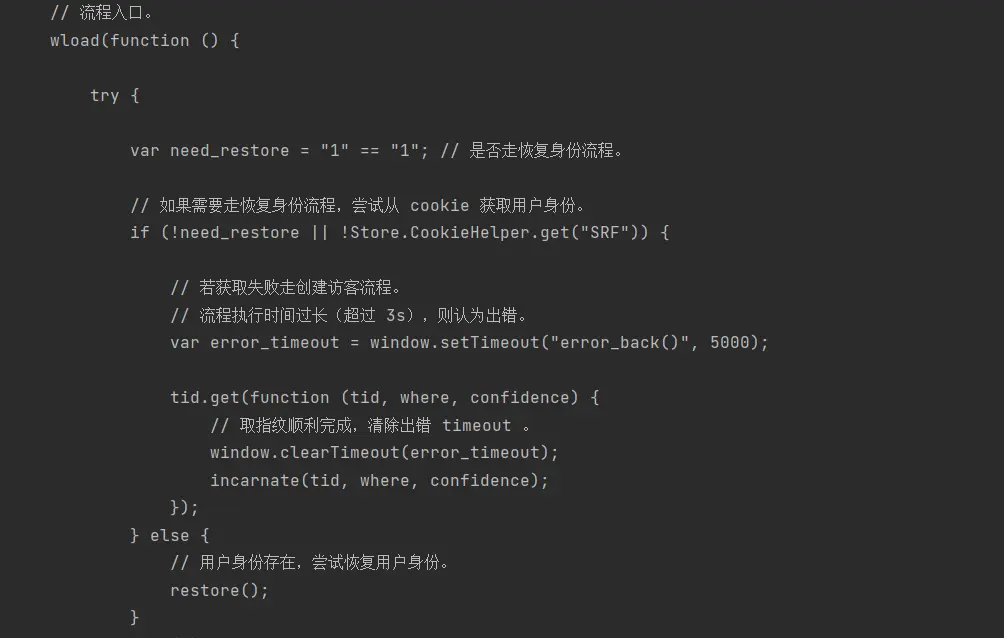
from tkinter import * import re from selenium import webdriver from selenium.webdriver.chrome.service import Service import time from bs4 import BeautifulSoup
defAskurl(url): s = Service(r"E:\python\PyCharm Community Edition 2021.3.1\plugins\python-ce\helpers\typeshed\stubs\selenium\selenium\webdriver\chrome\chromedriver.exe") option = webdriver.ChromeOptions() option.add_argument('headless') # 设置option driver = webdriver.Chrome(service=s,options=option) driver.get(url) print("请等待.....") for i inrange(1,7): print(str(i) +"/6") time.sleep(1) text = driver.page_source return text
datalist = []
defGtedata(url): Findtitle = re.compile(r'">(.*?)</a>') Findlink = re.compile(r'<a href="(.*?)" target="_blank">') # html=Askurl(url) print(html) soup=BeautifulSoup(html,"html.parser") for item in soup.find_all('td',class_="td-02"): data = [] item = str(item)
title = re.findall(Findtitle, item)[0] data.append(title)
if re.findall(Findlink,item): slink = re.findall(Findlink, item)[0] link = 'https://s.weibo.com' + str(slink) data.append(link)
datalist.append(data)
#输出测试 for index in datalist: print(index)
defjh(): root = Tk() v = IntVar() root.geometry('300x100') defselection(): se = str(v.get()) url = 'link' if se=='1': url = 'https://s.weibo.com/top/summary/' elif se=='2': url = 'https://s.weibo.com/top/summary/summary?cate=socialevent' elif se=='3': url = 'https://s.weibo.com/top/summary/summary?cate=entrank' Gtedata(url) root.destroy() Language = [('热搜榜', 1), ('要闻榜', 2), ('文娱榜', 3), ] for lang, num in Language: b = Radiobutton(root, text=lang, variable=v, value=num, indicatoron=False, padx=30, pady=3,command=selection) l = Label(root, textvariable=v) b.pack(anchor=W, fill=X) mainloop()