前言
这几天做图片爬虫上头了,感觉确实很方便但内容的重复性很大。掌握了一个网站的爬取方法就有很大的拓展空间,因此记录一下近期一个图片爬虫。
思路与实践
首先用浏览器的检查元素定位到网页首页图片
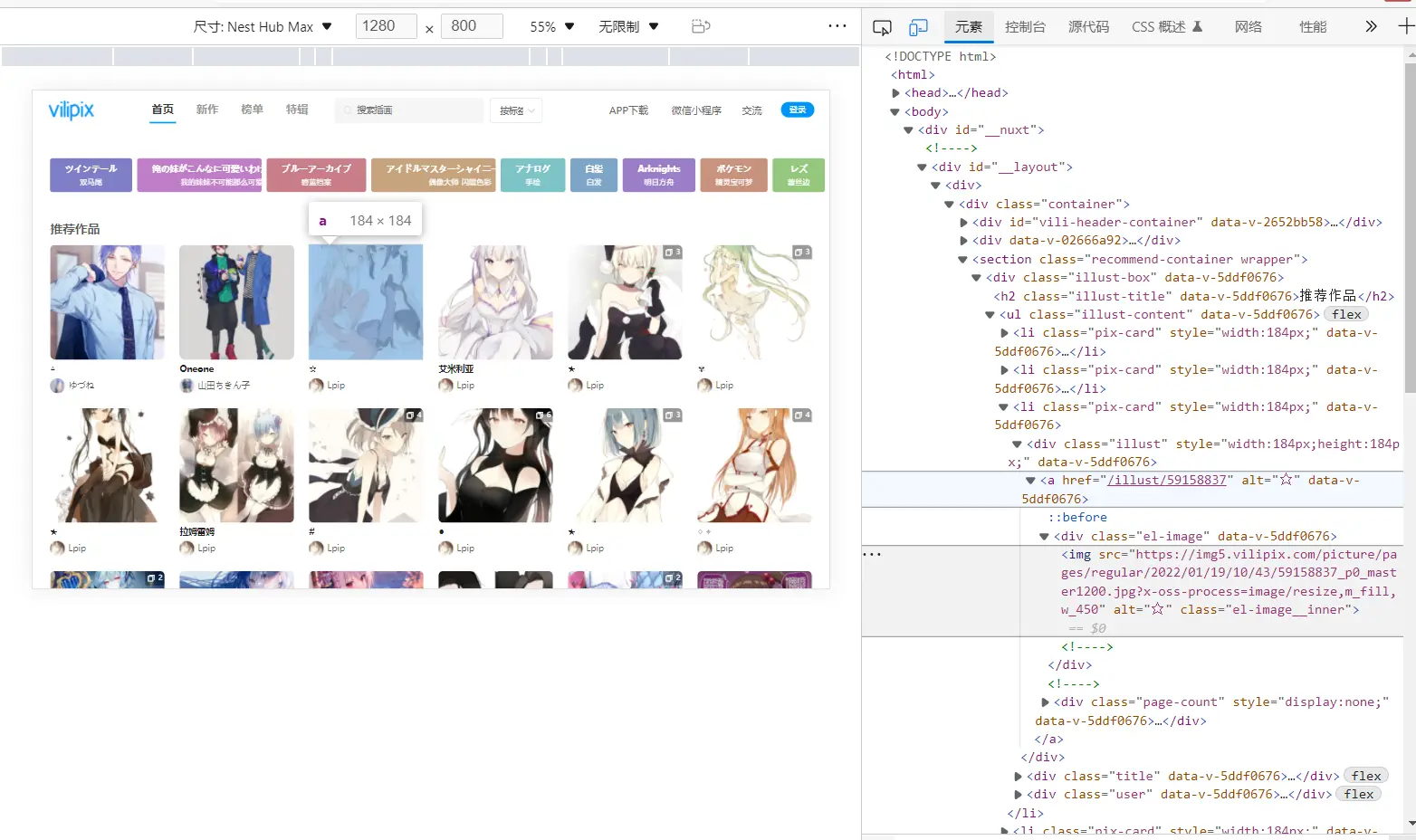
元素指向的是预览图,但想要获取的是原图,于是要跳转到详情页面再获取图片(如果能直接获取到图片id就更好了,但是我没找到。。。同时预览图的链接也没找到,如果能找到的话爬取效率会提升很多)
所以要获取的是 /illust/59158837 并进入指向的网页
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
| def Askurl(url):
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/81.0.4044.92 Safari/537.36'}
response = requests.get(url = url, headers = headers)
return response
linkdata = []
def Getlink(html):
Findlink = re.compile('href="(.*?)">', re.S)
soup = BeautifulSoup(html, "html.parser")
for item in soup.find_all('div', class_="illust"):
item = str(item)
try:
link = re.findall(Findlink, item)[0]
link = "https://www.vilipix.com" + str(link)
linkdata.append(link)
except:
print("no data")
|
获取子页源码之后可以顺利获取预览图链接,
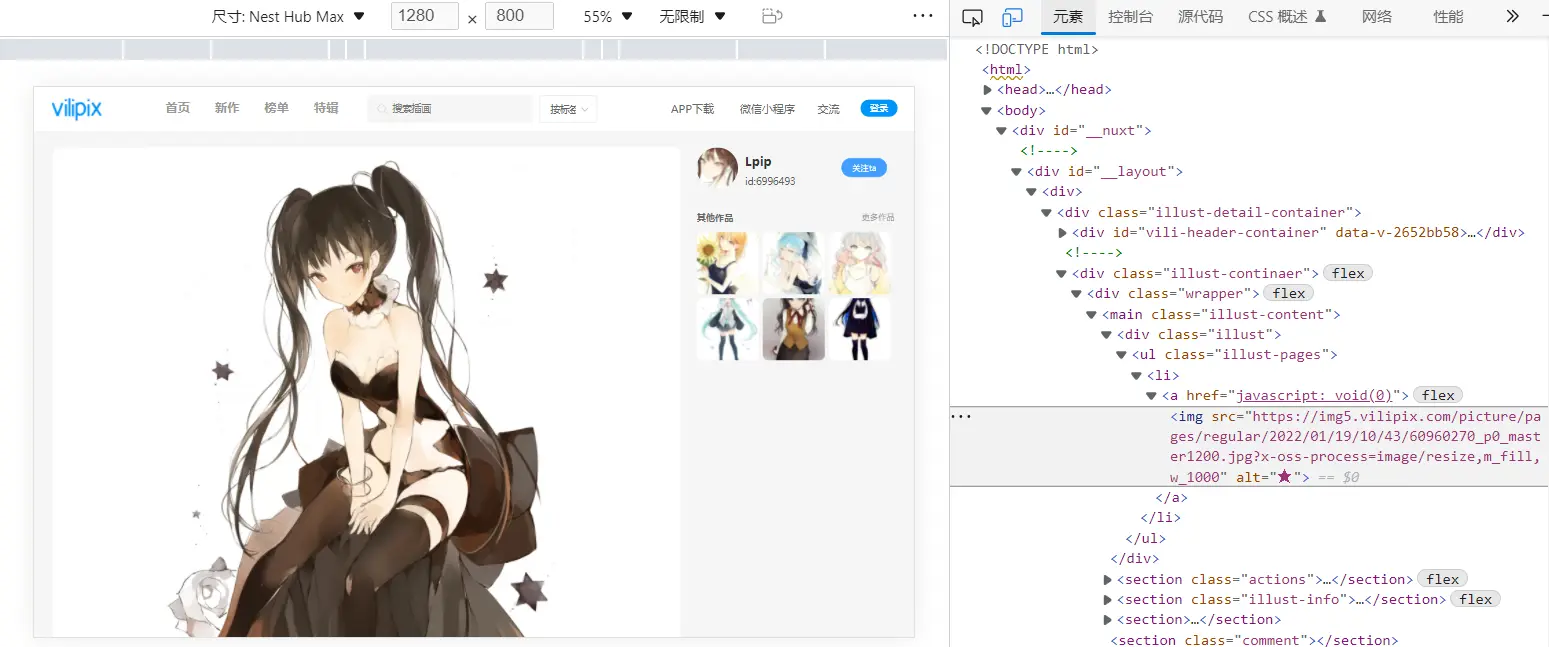
点击图片放大,右键复制图片链接,得到如下:
http://img5.vilipix.com/picture/pages/original/2022/01/19/10/43/59158837_p0.png
对比预览图链接可以找到特定规律
将预览图链接处理成获取源码的链接,
1
2
3
4
5
6
7
8
9
| if str(link.split("//")[-1].split(".")[0]) == "img5":
iurl = str(link.split("regular/")[0]) + "original/" + str(
link.split("regular/")[-1].split("_master")[0]) + ".jpg"
download(path,i,iurl,link)
else:
iurl = str(link.split("?")[0])
download(path,i,iurl,link)
|
最后进行批量图片下载即可,注意原图并非全部都是jpg格式,因此需要进行判断和修改
附源码
获取推荐图片
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
| import requests
from bs4 import BeautifulSoup
import re
import os
def Askurl(url):
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/81.0.4044.92 Safari/537.36'}
response = requests.get(url = url, headers = headers)
return response
linkdata = []
urldata = []
def Getlink(html):
Findlink = re.compile('href="(.*?)">', re.S)
soup = BeautifulSoup(html, "html.parser")
for item in soup.find_all('div', class_="illust"):
item = str(item)
try:
link = re.findall(Findlink, item)[0]
link = "https://www.vilipix.com" + str(link)
linkdata.append(link)
except:
print("no data")
def getpic(path):
i = 0
Findlink = re.compile('<img .*?src="(.*?)"', re.S)
for item in linkdata:
html = Askurl(item).text
soup = BeautifulSoup(html, "html.parser")
for item in soup.find('div', class_="illust"):
item = str(item)
try:
link = re.findall(Findlink, item)[0]
link = str(link)
if str(link.split("//")[-1].split(".")[0]) == "img5":
iurl = str(link.split("regular/")[0]) + "original/" + str(
link.split("regular/")[-1].split("_master")[0]) + ".jpg"
download(path,i,iurl,link)
else:
iurl = str(link.split("?")[0])
download(path,i,iurl,link)
i = i + 1
except:
print("no data")
def download(path,i,url,link):
bytes = Askurl(url).content
if not os.path.exists(path):
os.makedirs(path)
name = path + "image" + str(i+1) + ".jpg"
with open(name, "wb+") as f:
f.write(bytes)
if os.path.getsize(name) <=500:
os.remove(name)
print("获取错误,正在重试")
url = str(url.split(".jpg")[0]) + ".png"
bytes = Askurl(url).content
name = path + "image" + str(i + 1) + ".png"
with open(name, "wb+") as f:
f.write(bytes)
if os.path.getsize(name) <=500:
os.remove(name)
url = link
bytes = Askurl(url).content
name = path + "image" + str(i + 1) + ".png"
with open(name, "wb+") as f:
f.write(bytes)
if os.path.getsize(name) <=500:
print("获取失败")
else:
print("获取失败,已获取预览图片" )
else:
print("重试成功" + "(" +str(i+1) + "/" + str(len(linkdata)) +")")
else:
print(str(i+1) + "/" + str(len(linkdata)))
if (i+1) ==len(linkdata):
print("图片下载成功")
def main():
url = "https://www.vilipix.com/"
path = "Images/"
Getlink(Askurl(url).text)
getpic(path)
if __name__ == "__main__":
main()
|
排行榜图片
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
| import requests
from bs4 import BeautifulSoup
import re
import os
def Askurl(url):
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/81.0.4044.92 Safari/537.36'}
response = requests.get(url = url, headers = headers)
return response
linkdata = []
urldata = []
def Getlink(html):
Findlink = re.compile('" href="(.*?)">', re.S)
soup = BeautifulSoup(html, "html.parser")
for item in soup.find_all('div', class_="illust"):
item = str(item)
try:
link = re.findall(Findlink, item)[0]
link = "https://www.vilipix.com" + str(link)
linkdata.append(link)
except:
print("no data")
def getpic(path):
i = 0
Findlink = re.compile('<img .*?src="(.*?)"', re.S)
for item in linkdata:
html = Askurl(item).text
soup = BeautifulSoup(html, "html.parser")
for item in soup.find('div', class_="illust"):
item = str(item)
try:
link = re.findall(Findlink, item)[0]
link = str(link)
if str(link.split("//")[-1].split(".")[0]) == "img5":
iurl = str(link.split("regular/")[0]) + "original/" + str(
link.split("regular/")[-1].split("_master")[0]) + ".jpg"
download(path,i,iurl)
else:
iurl = str(link.split("?")[0])
download(path,i,iurl)
i = i + 1
except:
print("no data")
def download(path,i,url):
bytes = Askurl(url).content
if not os.path.exists(path):
os.makedirs(path)
name = path + "image" + str(i+1) + ".jpg"
with open(name, "wb+") as f:
f.write(bytes)
if os.path.getsize(name) <=500:
os.remove(name)
print("获取错误,正在重试")
url = str(url.split(".jpg")[0]) + ".png"
bytes = Askurl(url).content
name = path + "image" + str(i + 1) + ".png"
with open(name, "wb+") as f:
f.write(bytes)
if os.path.getsize(name) <=500:
os.remove(name)
print("获取失败")
else:
print("重试成功" + "(" +str(i+1) + "/" + str(len(linkdata)) +")")
else:
print(str(i+1) + "/" + str(len(linkdata)))
if (i+1) ==len(linkdata):
print("图片下载成功")
def main():
url = "https://www.vilipix.com/ranking?date=20220119&mode=monthly"
path = "RankImages/"
Getlink(Askurl(url).text)
getpic(path)
if __name__ == "__main__":
main()
|

